Understanding Retrieval Augmented Generation Architecture: A Comprehensive Overview
Retrieval Augmented Generation (RAG) represents a significant advancement in the field of artificial intelligence, specifically enhancing large language models (LLMs) by incorporating external knowledge retrieval mechanisms. The diagram shared in the query illustrates the fundamental flow of a RAG system, showing how user queries are processed through various components before generating a contextually enriched response. This comprehensive analysis examines the architecture, components, workflows, and implementations of RAG systems to provide a thorough understanding of this increasingly important AI paradigm. Maintaining high data quality is essential for RAG systems to ensure ethical AI development and compliance with privacy regulations.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a cutting-edge software architecture designed to enhance large language models (LLMs) by integrating them with relevant data from external sources. This innovative approach combines the strengths of both retrieval and generation, resulting in more accurate and informative responses. At the heart of RAG is the use of vector databases and semantic search, which enable the system to retrieve relevant information from a vast knowledge base. By leveraging these technologies, RAG systems can access proprietary business data and other external sources, providing contextually enriched responses that are both precise and relevant. This dual capability of retrieval and generation allows RAG to overcome the limitations of standalone LLMs, making it a powerful tool for a wide range of applications.
Foundations of RAG Architecture
Retrieval Augmented Generation fundamentally transforms how language models interact with information by supplementing their parametric knowledge with dynamically retrieved data. RAG architecture can deploy any LLM model without the costs and time of fine-tuning or pretraining. At its core, RAG addresses critical limitations of standalone LLMs, such as knowledge cutoffs, hallucinations, and domain-specific expertise gaps. The basic architecture depicted in the flowcharts represents the standard sequential processing of information from user input to generated output.
Simple RAG
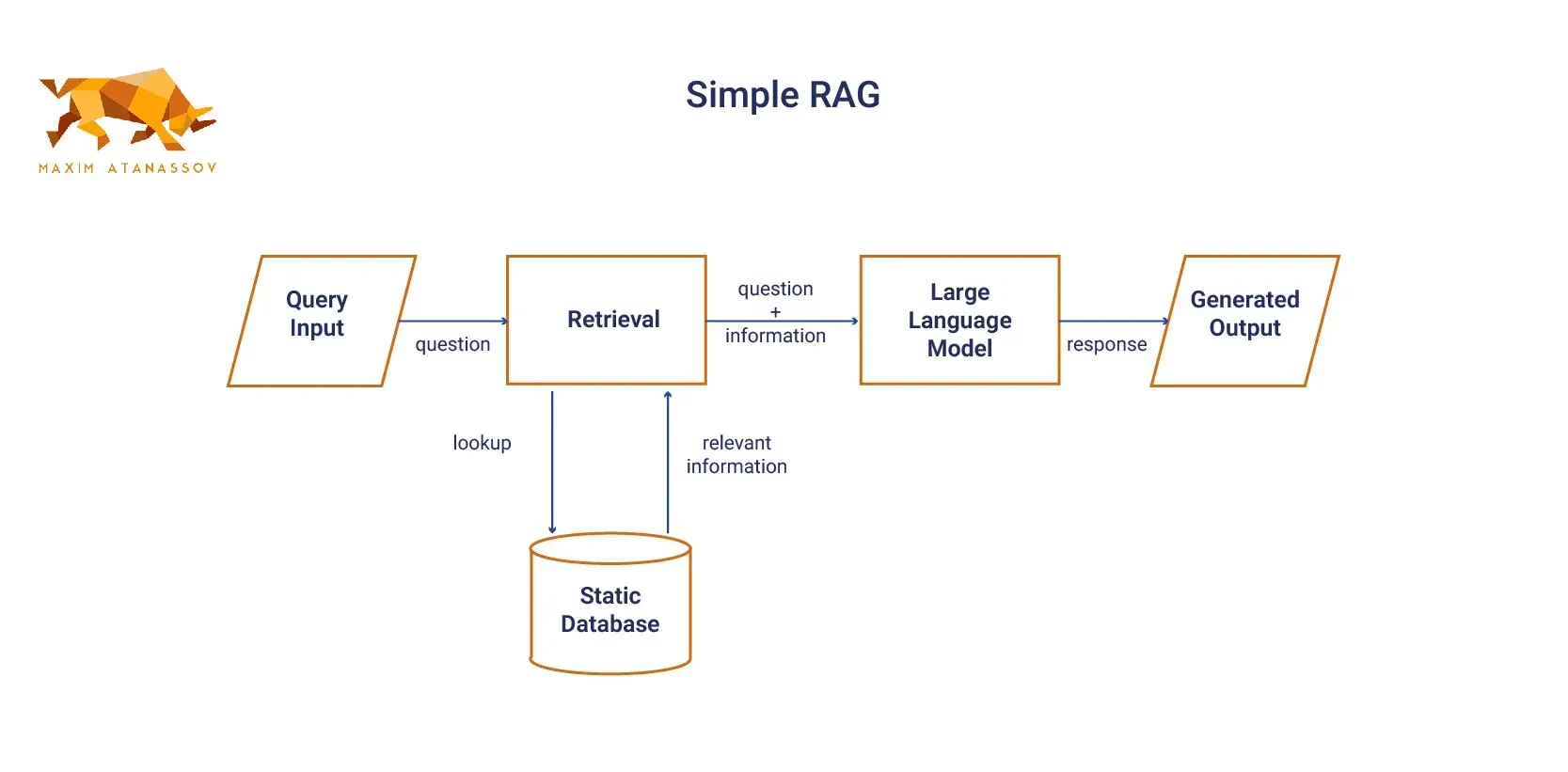
The simplest form of RAG architecture, often referred to as Simple RAG. It follows a straightforward flow where a user query triggers a retrieval process from external data sources before generation occurs.
This is the most basic form of RAG. In this configuration, the language model retrieves relevant documents from a static database in response to a query, and then generates an output based on the retrieved information. This straightforward implementation works well in situations where the database is relatively small and doesn’t require complex handling of large or dynamic datasets.
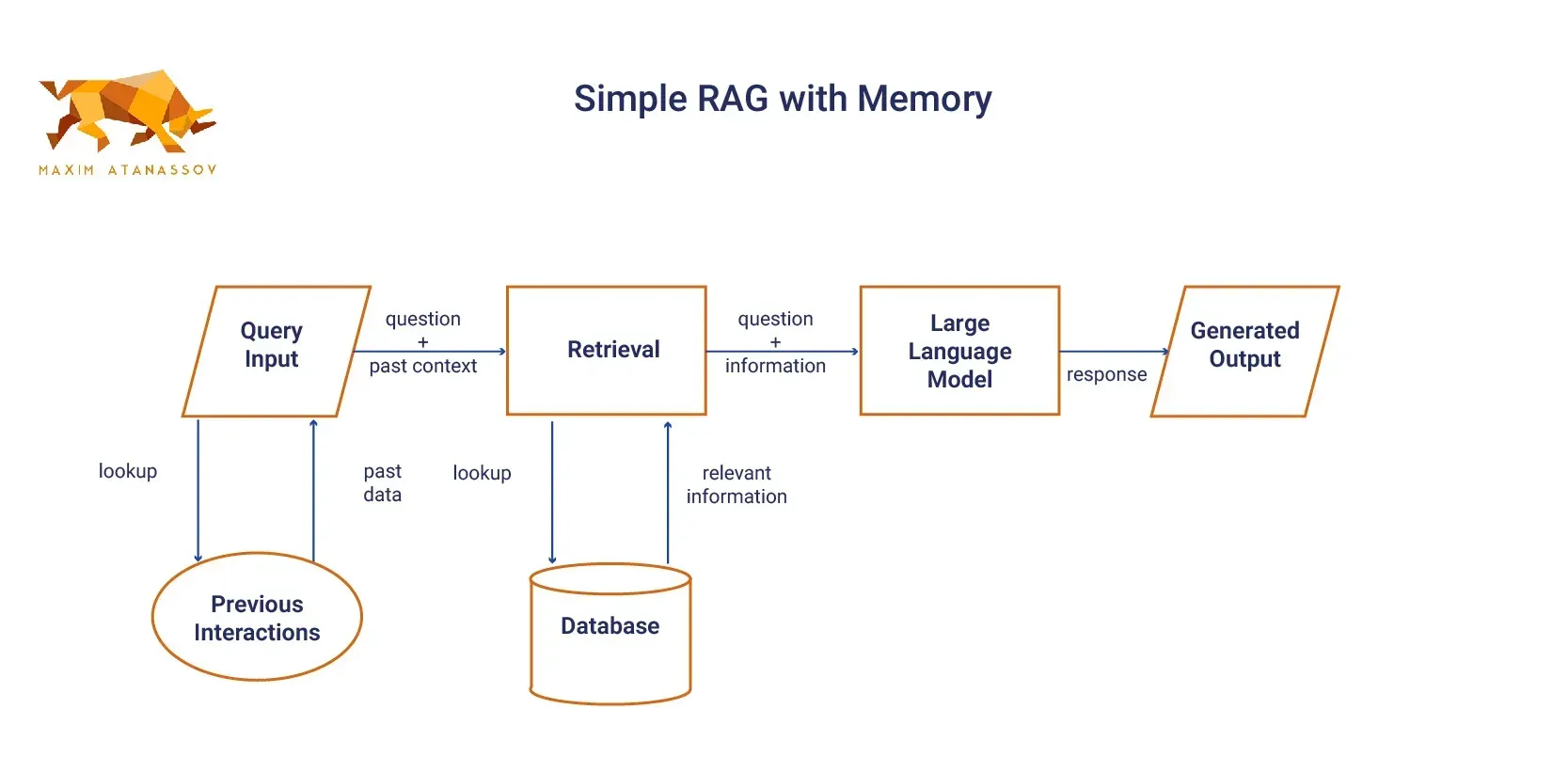
Simple RAG with Memory
Simple RAG with Memory includes a storage component that allows the model to retain information from prior interactions. This improvement enhances its ability for continuous conversations or tasks that require contextual awareness across several queries. Prompt caching can be used with Simple RAG to achieve this.
This architecture has evolved considerably since its introduction by Facebook AI Research (now Meta AI) in 2020, which described RAG as a "general-purpose fine-tuning recipe" designed to connect any LLM with any knowledge source. Today's implementations range from basic implementations to sophisticated systems with multiple retrieval paths and advanced processing techniques.
Core Components of RAG Systems
The standard RAG architecture consists of several key components that work in coordination to transform user queries into informed responses. Each component serves a specific function in the information processing pipeline:
- User Query Interface: The entry point of any RAG system begins with a user's query. This component accepts natural language queries from users and serves as the initial trigger for the entire process. User queries can range from simple factual questions to complex analytical requests requiring the synthesis of multiple information sources. The interface must effectively capture user intent to ensure subsequent processes retrieve relevant information.
- Orchestrator: The orchestrator functions as the central coordinator within the RAG architecture, managing the flow of information between components. It receives the user query, determines appropriate retrieval strategies, coordinates with various system components, and ultimately manages the final response generation. Modern orchestrators are often implemented using frameworks like Semantic Kernel, Azure Machine Learning prompt flow, or LangChain. The orchestrator's sophistication largely determines the overall system's ability to handle complex information needs.
- Retriever and Vector Database: This critical component performs the actual information retrieval, searching through external knowledge sources to find content relevant to the user query. The retrieval system typically converts both the query and stored documents into vector representations (embeddings) to enable semantic matching. Modern implementations incorporate vector databases which store pre-processed document embeddings for efficient similarity searching. The effectiveness of the retriever significantly impacts the quality of generated responses, as it determines what contextual information is made available to the language model. Transforming and enriching data is crucial to improve the relevancy of the search results returned to users.
- Prompt Augmentation: Once relevant information is retrieved, the prompt augmentation component integrates this external knowledge with the original user query to create an enhanced prompt for the LLM. This augmentation process uses prompt engineering techniques to effectively communicate retrieved context to the language model. The augmented prompt allows the LLM to generate responses grounded in both its pretrained knowledge and the specifically retrieved information, dramatically improving response accuracy and relevance.
- Large Language Model (LLM): The LLM serves as the generative component, processing the augmented prompt to produce coherent, contextually appropriate responses. Without RAG, the LLM would rely solely on its parametric knowledge from training data. With RAG, the model benefits from fresh, contextually relevant information retrieved at inference time. This combination enables the LLM to produce responses that reflect both its general language capabilities and specific retrieved facts.
- Generated Response: The final output returned to the user represents the synthesis of retrieved information and the LLM's generative capabilities. A well-designed RAG system produces responses that are not only factually accurate but also coherently structured and contextually appropriate to the user's original query.
RAG System Workflows: Indexing and Retrieval
The operational flow of a RAG system can be divided into two principal workflows: the indexing process and the retrieval-generation process. Understanding both is essential for comprehending how RAG architectures function holistically.
Indexing Workflow
Before any retrieval can occur, a RAG system must process and index external knowledge sources through a Load-Transform-Embed-Store pipeline:
Data loading involves gathering information from diverse sources including unstructured documents (PDFs, text files), semi-structured data (JSON, XML), and structured databases. Document splitters then segment this information into manageable chunks while preserving semantic coherence—typically breaking documents into paragraphs or logical sections. The tokenizer converts these text segments into tokens (words, subwords, or characters) that serve as the fundamental units for processing. An embedding model then transforms these tokens into high-dimensional vector representations that capture semantic meaning. Finally, these vectors and associated metadata are stored in a vector database optimized for similarity searching.
This indexing process typically occurs offline, separate from the real-time query processing workflow. The quality of indexing directly impacts retrieval performance, making it a critical consideration in RAG system design.
Retrieval and Generation Workflow
When a user submits a query, the RAG system follows a sequence of operations to generate a response based on the user's query:
The user query is processed through the same tokenization and embedding pipeline used during indexing to create a vector representation. The orchestrator then leverages this query embedding to search the vector database for semantically similar content. Retrieved documents are ranked by relevance, with the most pertinent information selected for inclusion in the augmented prompt1. The orchestrator combines the original query with these retrieved passages to create an enhanced prompt for the LLM. The LLM processes this enriched prompt to generate a comprehensive response that incorporates both its parametric knowledge and the retrieved information. The final response is then returned to the user.
Throughout this process, components like the tokenizer and embedding model play critical roles in both the indexing and retrieval workflows, effectively establishing a common language that enables consistent processing throughout the entire architecture.
Advanced RAG Architectures
While the basic RAG flow represented in the diagrams above provide a foundation, several more sophisticated architectural patterns have emerged to address complex use cases:
- Branched RAG: Branched RAG enables a more flexible and efficient approach to data retrieval by determining which specific data sources should be queried based on the input. Instead of querying all available sources, Branched RAG evaluates the user's query to intelligently select the most relevant data sources, optimizing the retrieval process. This selective querying not only reduces the computational overhead but also enhances the accuracy of the retrieved information by focusing on the most pertinent sources. Branched RAG is particularly useful in scenarios where data sources are numerous and diverse, allowing the system to adapt dynamically to the context of each query. By leveraging advanced algorithms and decision-making processes, Branched RAG ensures that the retrieval process is both efficient and effective, providing high-quality inputs to the language model for generating precise and contextually enriched responses.
- HyDe (Hypothetical Document Embedding): HyDe is a unique RAG variant that generates hypothetical documents based on the query before retrieving relevant information. Instead of directly retrieving documents from a database, HyDe first creates an embedded representation of what an ideal document might look like, given the query. It then uses this hypothetical document to guide retrieval, improving the relevance and quality of the results. This innovative approach allows HyDe to simulate potential answers by constructing a conceptual understanding of the query's intent. By doing so, it can anticipate the type of information that would most effectively address the user's needs. This simulation not only enhances retrieval accuracy but also aids in filtering out irrelevant data, ensuring that only the most pertinent information is considered. Furthermore, HyDe's ability to create these hypothetical constructs makes it particularly effective in scenarios where direct matches are scarce or when dealing with highly specialized queries that require nuanced understanding. By leveraging this advanced technique, HyDe can significantly improve the performance of RAG systems, offering more precise
- Multi-Stage RAG: This architecture implements a sequential retrieval process where initial results are used to refine subsequent retrievals. By decomposing complex queries into sub-questions and retrieving information iteratively, multi-stage RAG can handle more complex information needs than simple single-pass approaches.
- Multi-Stage RAG stands out for its ability to tackle intricate queries by breaking them down into manageable parts. This method is akin to a strategic chess game, where each move builds upon the last to achieve a more comprehensive understanding of the user's query. Initially, the system retrieves a broad set of relevant documents or data points. These initial results are then analyzed to identify gaps or areas requiring further exploration. The system subsequently formulates new, more focused queries, diving deeper into specific aspects of the original question. This iterative process continues until a satisfactory level of detail and accuracy is achieved.
- The strength of Multi-Stage RAG lies in its adaptability and precision. By iteratively refining its search, the system can explore multiple data sources and perspectives, ensuring that the final response is both thorough and nuanced. This approach is particularly beneficial in domains requiring detailed analysis, such as legal research, scientific exploration, or complex decision-making scenarios. Furthermore, by leveraging advanced algorithms and machine learning techniques, Multi-Stage RAG can dynamically adjust its retrieval strategy, optimizing for both speed and accuracy. This makes it an invaluable tool for organizations seeking to harness the full potential of their data assets in an ever-evolving information landscape.
- Hybrid Search RAG: Hybrid approaches combine vector similarity search with traditional keyword-based methods to leverage the strengths of both paradigms. This architecture often produces more robust retrieval results by balancing semantic understanding with exact matching techniques.
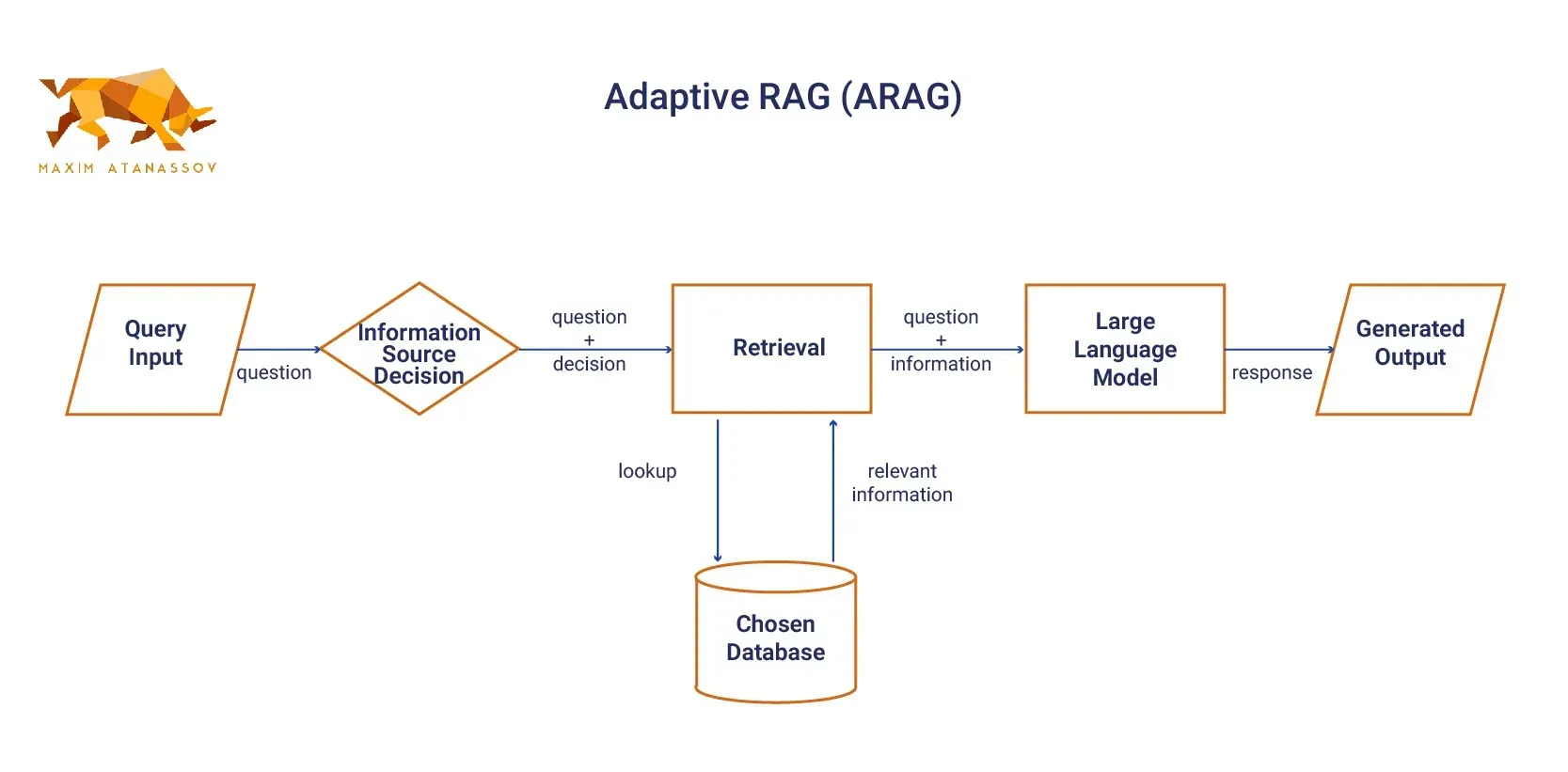
- Adaptive RAG (ARAG): **Adaptive RAG systems are designed to dynamically adjust their retrieval strategies based on the characteristics of the user's query or the results from initial retrieval attempts. This adaptability is achieved through the intelligent selection of different retrieval methods or the on-the-fly adjustment of retrieval parameters to optimize performance across a diverse array of query types. By analyzing the query's complexity, context, and the type of information being sought, ARAG can determine the most effective retrieval strategy, whether it involves semantic search, keyword-based retrieval, or a hybrid approach. This flexibility allows ARAG to efficiently handle a wide range of queries, from simple factual questions to complex analytical tasks that require synthesizing information from multiple sources. Additionally, ARAG systems can incorporate feedback loops that learn from past retrieval successes and failures, continuously refining their strategies to improve accuracy and relevance over time. This makes ARAG a powerful tool for applications where query diversity and information complexity are high, such as customer support, research, and dynamic content generation.
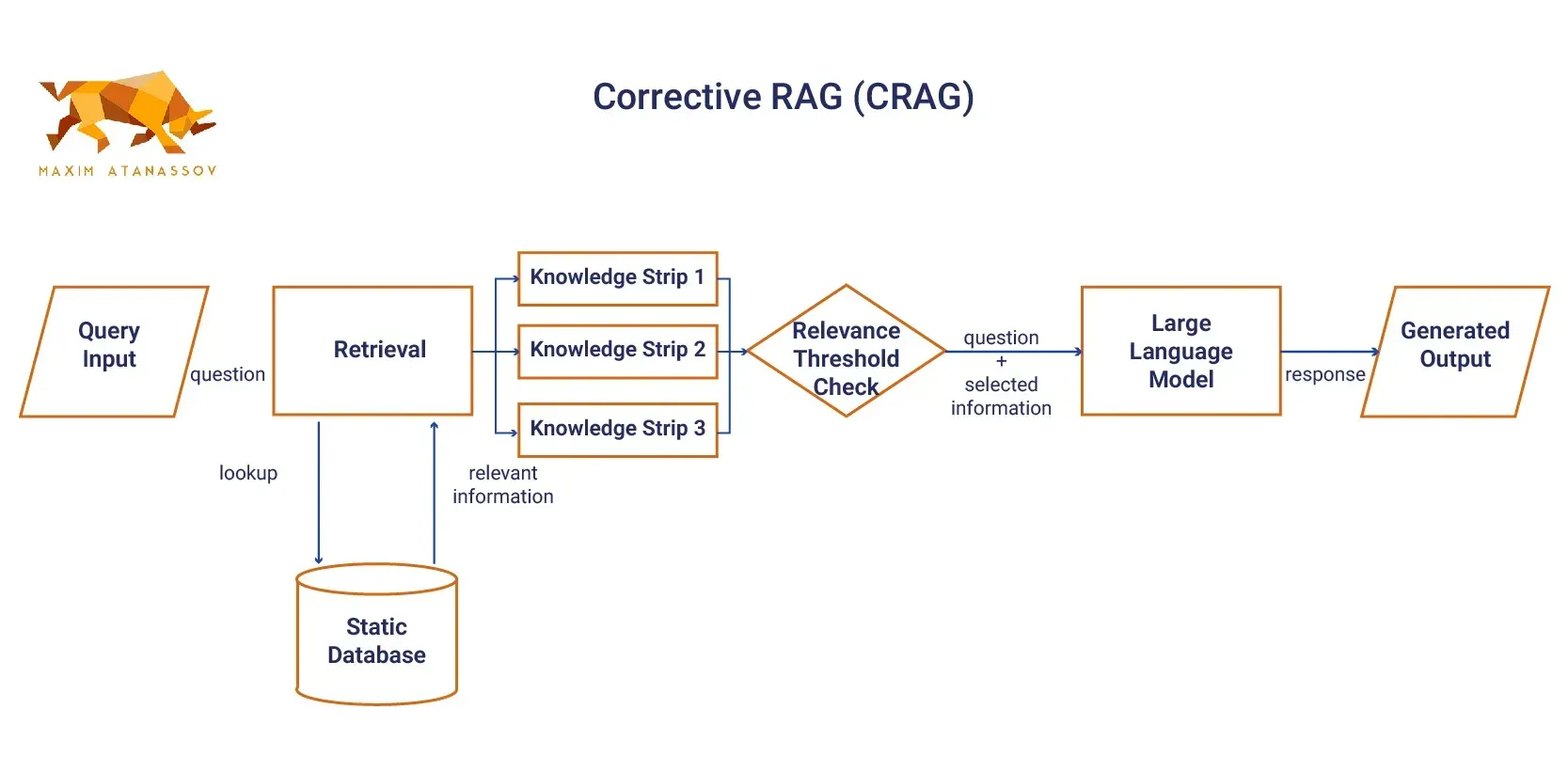
- Corrective RAG (CRAG): Corrective RAG introduces a self-reflection or self-grading mechanism to enhance the accuracy and relevance of generated responses. Unlike traditional RAG models, CRAG critically assesses the quality of the information retrieved before proceeding to the generation phase. By dividing retrieved documents into "knowledge strips," CRAG evaluates each strip for relevance and factual accuracy. If the initial retrieval does not meet a specified relevance threshold, CRAG initiates additional retrieval steps, such as web searches or querying multiple data sources, to ensure it possesses the most accurate and comprehensive information for generating the output. This iterative process allows CRAG to refine its retrieval strategy dynamically, improving the overall quality of the generated responses. By leveraging advanced algorithms and machine learning techniques, CRAG can adapt to various query complexities and information needs, ensuring that the final output is both precise and contextually enriched. This makes CRAG particularly valuable in domains where factual accuracy and up-to-date information are critical, such as medical diagnosis, legal research, and financial analysis. Furthermore, CRAG's ability to self-correct and optimize retrieval processes positions it as a robust solution for organizations seeking to enhance their AI-driven decision-making capabilities.
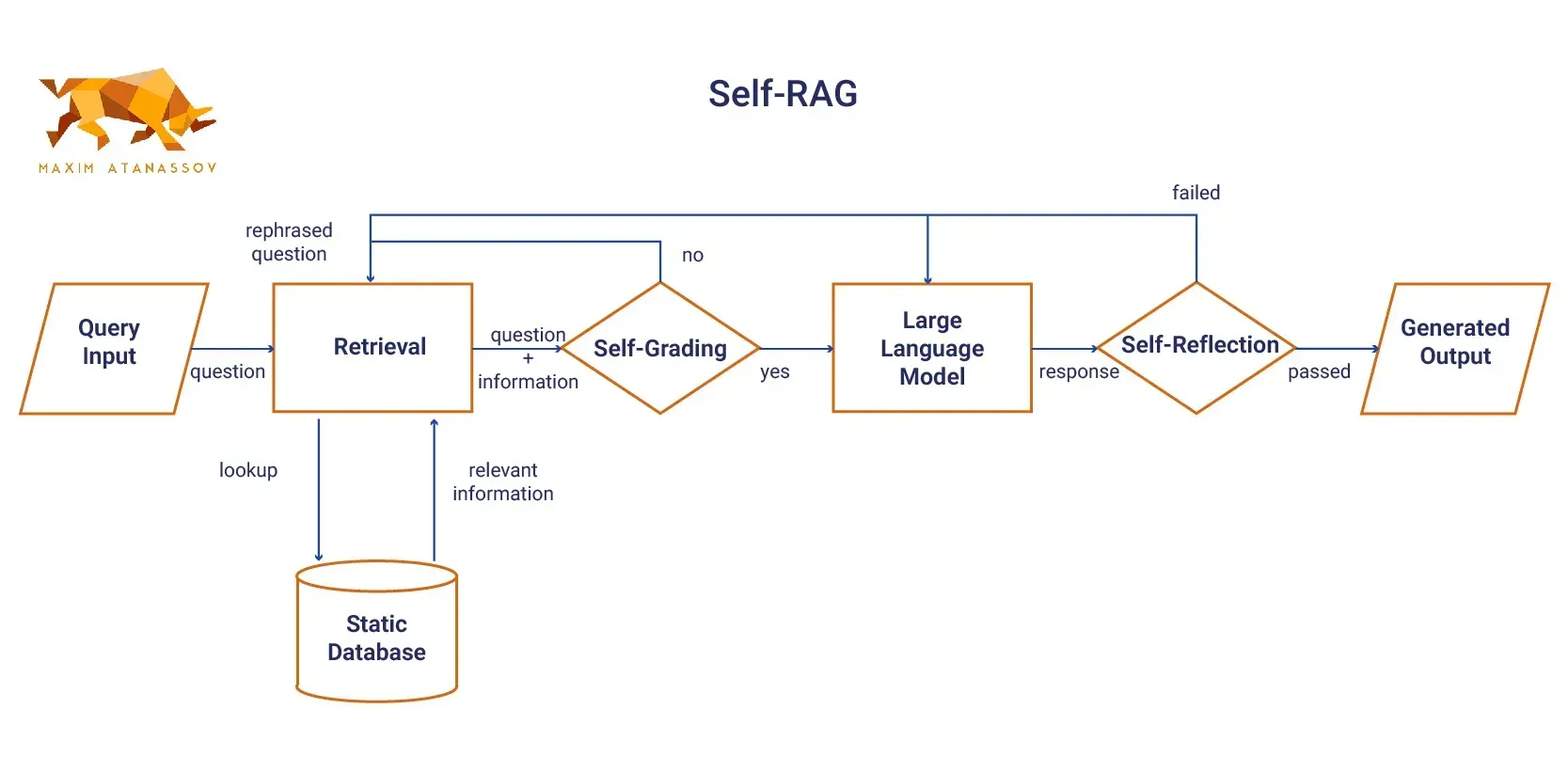
- Self-RAG: Self-RAG introduces a self-retrieval mechanism, enabling the model to autonomously create retrieval queries throughout the generation process. In contrast to traditional RAG models, where retrieval relies solely on the user’s input, Self-RAG can iteratively refine its queries as it generates content. This self-guided approach improves the quality and relevance of information, particularly for complex or evolving queries.By autonomously generating its retrieval queries, Self-RAG can continuously adapt to new information and context, allowing it to provide more accurate and up-to-date responses. This dynamic capability is especially beneficial in scenarios where the nature of the query may change over time or when dealing with incomplete data sets. As the model generates content, it assesses the need for additional information, initiating further retrieval processes as necessary. This iterative refinement not only enhances the depth of the generated content but also ensures that the system can address more nuanced and multifaceted queries. Moreover, Self-RAG's ability to self-retrieve allows it to operate more independently, reducing the dependency on predefined retrieval paths and enabling a more flexible response generation. This adaptability is crucial for applications such as customer support bots, where queries can be diverse and unpredictable. By leveraging machine learning techniques, Self-RAG can learn from past interactions, refining its retrieval strategies to better meet user needs over time. The incorporation of self-retrieval mechanisms positions Self-RAG as a robust solution for environments requiring high levels of precision and adaptability, ensuring that users receive the most relevant and comprehensive information available.
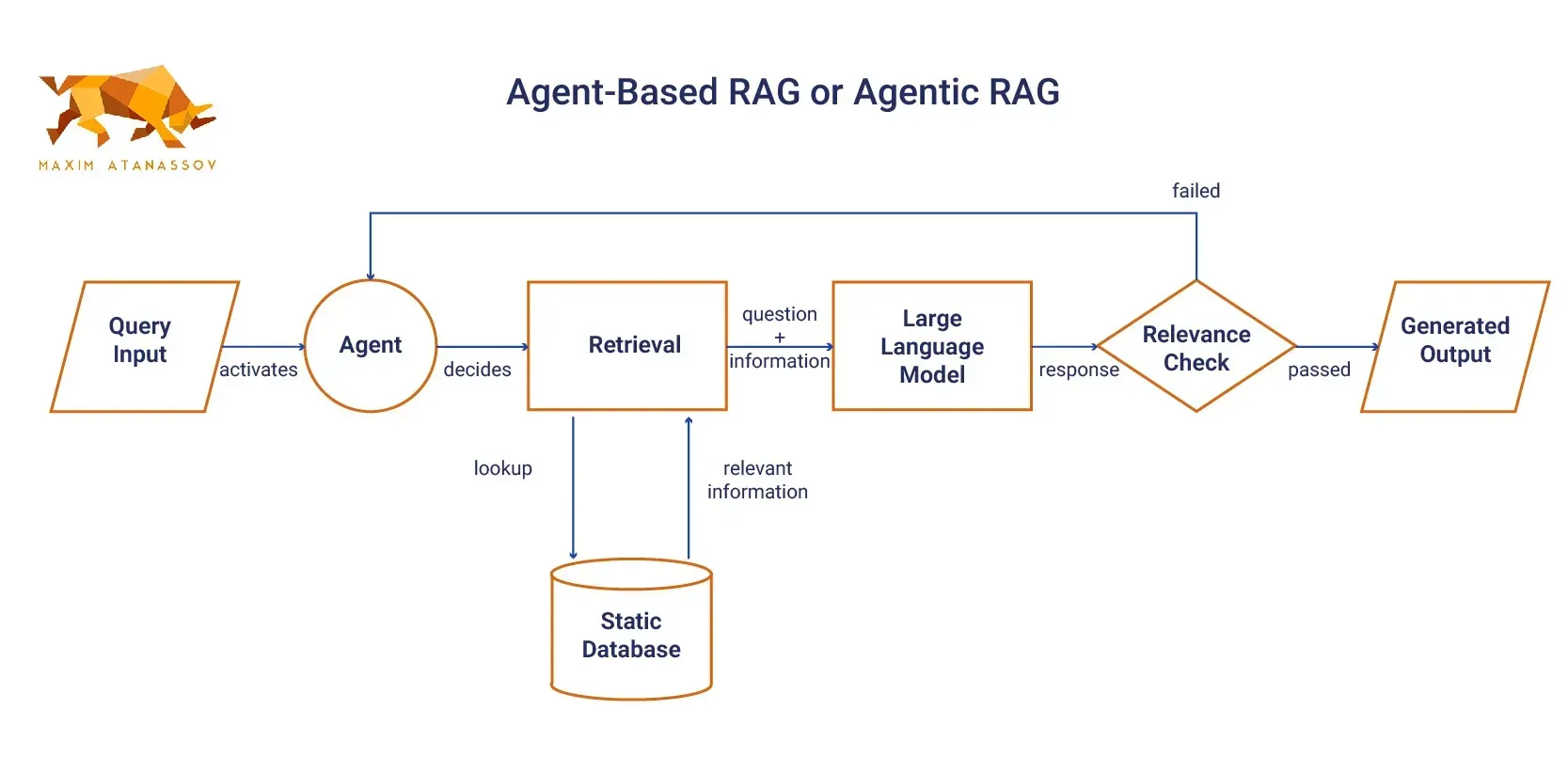
- Agent-Based RAG or Agentic RAG: More advanced implementations incorporate LLM-powered agents capable of performing complex reasoning over retrieved information. These agents can potentially access multiple knowledge sources and tools to meet information needs beyond mere fact retrieval.
Fine-Tuning and Adaptation
Fine-tuning and adaptation are pivotal steps in the RAG pipeline, ensuring that the system can generate accurate and contextually appropriate responses. Fine-tuning involves retraining a pre-trained LLM on a specific dataset, allowing it to adapt to particular tasks or domains. This process helps the LLM learn the nuances of the data, resulting in more precise and relevant outputs. Adaptation, on the other hand, involves adjusting the RAG system to accommodate changes in data or user queries. Techniques such as prompt engineering play a crucial role in this process, refining input prompts to elicit more accurate responses from the LLM. By continuously fine-tuning and adapting, RAG systems can maintain high performance and relevance across diverse applications.
Continuous Learning and Updatingw post
Continuous learning and updating are essential for maintaining the accuracy and relevance of RAG systems over time. As new data becomes available, the RAG system must be updated to incorporate this information, ensuring that it remains current and effective. Incremental learning is a key technique in this process, allowing the LLM to be updated with new data without requiring a full retraining. Additionally, user feedback is invaluable for refining the RAG system, providing insights that can be used to improve its performance. By embracing continuous learning and updating, RAG systems can adapt to evolving data landscapes and user needs, delivering consistently accurate and relevant responses.
Implementation Considerations
Implementing an effective RAG architecture requires careful attention to several critical factors that influence system performance:
- Resource Management: The shared components in RAG architectures—particularly tokenizers and embedding models—operate across both indexing and retrieval workflows, creating resource dependencies that must be carefully managed. Effective infrastructure planning must account for these shared resource requirements rather than focusing exclusively on the LLM and vector database components.
- Scaling Challenges: As data volumes grow and more sources are integrated, RAG systems must scale accordingly. This scaling challenge is particularly pronounced during batch indexing operations, which can create irregular resource utilization patterns. Flexible resource allocation models and scalable infrastructure solutions are essential for maintaining performance as systems expand.
- Evaluation Methods: Rigorous evaluation is crucial for RAG system design and optimization. This involves systematically testing document selection, chunking strategies, embedding models, search configurations, and prompt engineering techniques to identify optimal configurations for specific use cases. A scientific approach to evaluation helps ensure that architectural decisions are based on measurable performance improvements rather than assumptions.
Hardware Acceleration and Scalability
Deploying RAG systems in production environments requires robust hardware acceleration and scalability. Specialized hardware, such as graphics processing units (GPUs) and tensor processing units (TPUs), can significantly accelerate RAG systems, enabling them to handle large volumes of data and user queries efficiently. Scalability is equally important, and techniques such as distributed computing and cloud deployment can be employed to ensure that RAG systems can scale seamlessly to meet growing demands. By leveraging these technologies, organizations can deploy RAG systems that are both powerful and scalable, capable of delivering high performance in real-world applications.
Data Governance and Security
Data governance and security are critical components of any RAG system, ensuring the integrity and trustworthiness of the data it processes. Implementing robust security measures is essential to protect sensitive data sources and ensure compliance with relevant data governance regulations. Techniques such as data anonymization and encryption can be used to safeguard user data, maintaining confidentiality and trust. By prioritizing data governance and security, organizations can ensure that their RAG systems are reliable, trustworthy, and compliant with regulatory requirements, providing a solid foundation for their AI-driven initiatives.
Benefits and Applications of RAG Architecture
The RAG architecture provides several compelling advantages over traditional LLM implementations:
- Enhanced Accuracy and Reliability: By grounding LLM responses in retrieved information, RAG significantly reduces hallucinations and factual errors. This is particularly valuable in domains where accuracy is paramount, such as healthcare, legal, or financial applications.
- Domain Adaptation: RAG enables LLMs to access specialized knowledge without complete retraining, making it easier to adapt general-purpose models to specific domains. This allows organizations to leverage their proprietary information while benefiting from the linguistic capabilities of large foundation models.
- Information Currency: Unlike static LLM knowledge that becomes outdated after training, RAG systems can access the latest information through their retrieval mechanisms. This dynamic knowledge integration ensures responses reflect current information, which is essential for rapidly evolving domains.
- Enterprise Integration: For organizations, RAG architecture provides a pathway to securely integrate proprietary data with generative AI capabilities. By constraining LLMs to authorized enterprise content, organizations can implement AI solutions that respect information boundaries while delivering valuable insights.
Conclusion
Retrieval Augmented Generation represents a transformative approach to language model applications, creating systems that combine the linguistic capabilities of LLMs with the factual precision of information retrieval. The architecture depicted in the various flowcharts above captures the essential components and relationships that define this paradigm, though in practice, implementations continue to evolve with increasing sophistication.
As RAG technologies mature, we can expect to see further refinements in retrieval techniques, more complex orchestration strategies, and tighter integration between retrieval and generation processes. These advancements will continue to enhance the accuracy, reliability, and applicability of AI language systems across an expanding range of domains and use cases.
CONTENT




Share

Maxim Atanassov, CPA-CA
Serial entrepreneur, tech founder, investor with a passion to support founders who are hell-bent on defining the future!
I love business. I love building companies. I co-founded my first company in my 3rd year of university. I have failed and I have succeeded. And it is that collection of lived experiences that helps me navigate the scale up journey.
I have found 4 companies to date that are scaling rapidly.